
Gradient Ascent #4
Deep RL, representation learning, neuroscience, rewards

Welcome to the 4th edition of Gradient Ascent. I’m Albert Azout, a prior entrepreneur and current Partner at Cota Capital. On a regular basis I encounter interesting scientific research, startups tackling important and difficult problems, and technologies that wow me. I am curious and passionate about machine learning, advanced computing, distributed systems, and dev/data/ml-ops. In this newsletter, I aim to share what I see, what it means, and why it’s important. I hope you enjoy my ramblings!
Is there a founder I should meet?
Send me a note at albert@cotacapital.com
Want to connect?
Find me on LinkedIn, Angelist, Twitter
DeepMind published a whitepaper called Deep Reinforcement Learning and Its Neuroscientific Implications, which I found quite fascinating…
How much of what we learn is formed by goal-directed behavior?
The human brain did not evolve in isolation. It co-evolved with its environment, over millions of years. Our brain drives our actions, our actions feed survival, and our survival drives reproduction—the propagation of our genes. To act, our brain must first predict the future state of world. We act. The world responds with a realized state. The state is rewarding or punitive, depending on the quality of our predictions (and maybe some luck). Our brains then adapt, adjusting our future predictions and actions. The loop continues 🧠…
Supervised deep learning models (the majority of models today) are trained outside the context of an environment. They are told what is right and wrong up front, by way of labeled training data. There is no loop. While the training data is accumulated from the real world, there is no active feedback signal during the training process. The training objective is aimed at minimizing explicit loss (e.g. classification error). In the real world, however, being correct is more dynamic, complex, and often not (immediately) obvious.
Deep neural networks have proved to be an outstanding model of neural representation. However, this research has for the most part used supervised training and has therefore provided little direct leverage on the big-picture problem of understanding motivated, goal-directed behavior within a sensory-motor loop [Deep Reinforcement Learning and Its Neuroscientific Implications].
Learning through interaction…
Reinforcement learning (RL) models an agent interacting in an environment. The goal of RL is to learn a policy that maximizes the agent’s long-term reward. The learned policy maps the state of the environment to an (optimal) agent action.
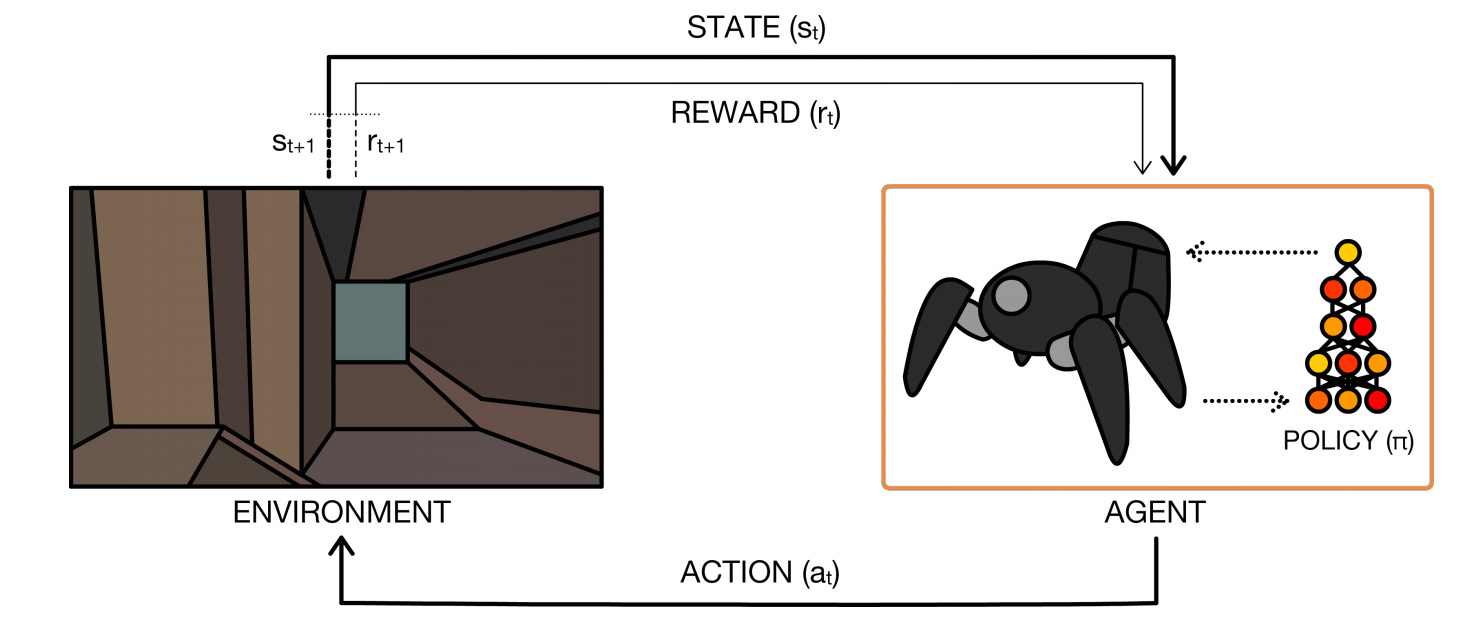
RL considers the problem of a learner or an agent embedded in an environment, where the agent must progressively improve the actions it selects in response to each environmental situation [Deep Reinforcement Learning and Its Neuroscientific Implications].
Modern RL approaches utilize deep learning (DL)…
DL utilizes multiple layers of networks to learn complex features from sensory input (i.e. representation learning—deriving a set of features from perceptual inputs). Deep RL combines deep learning + RL to address problem settings with high-dimensional state and action spaces (e.g. a Deep RL DQN network playing Space Invaders, below). See [A Brief Survey of Deep Reinforcement Learning] for a survey of Deep RL.
The DeepMind paper provokes an interesting thought…
In combining DL with RL, deep RL algorithms learn feature representations that are shaped by task requirements and rewards (the functional implications to the agent’s task). On the contrary, supervised DL systems learn representations that associate images by similarity in terms of high-level features (in the case of vision). In the image below, (a) is a low-dimensional embedding (t-SNE) of images from a supervised DL net where colors represent classes and closeness in space implies image similarity, and (b) is a low-dimensional embedding of Atari video game images from a deep RL game-playing model, colored by predicted future reward, where closeness in the embedding represents similarity in terms of implications for winning the game.

In the context of our own brains, an interesting question to ask is whether we learn to associate perceptual inputs by high-level feature similarity (i.e. this is a dog, dogs have tails). Or rather, do we first learn skills, and associate perceptual inputs by features relevant to completing tasks (i.e. I need to open doors, door handles are used for opening doors)? Perhaps both types of representations are somehow convolved in our minds.
Some thoughts:
The goal of Artificial General Intelligence is to develop intelligent agents that can act in any environment, regardless of their training context. An interesting area of research is Learning to Reinforcement Learn where the goal is to develop deep RL methods that can adapt and generalize rapidly to new tasks (meta-learning). Being able to learn across tasks requires a higher level of abstraction—I think we will learn a lot about human thinking leveraging this approach.
I think we will see an uptick in RL use cases in the wild, as we move from a centralized cloud to a decentralized edge, with the proliferation of connected, embedded devices (IoT) that can sense/decide in software and sense/actuate physically.
The Ray distributed computing framework will start to get adoption for RL use cases, but also for distributed workflows as a generalized serverless substrate, letting developers quickly scale and parallelize their applications with minimal coding.
Exciting times for RL research…
Non Sequiturs
Insightful keynote presentation by Ion Stoica at the Ray Summit about the progression of distributed computing:
I started messing around with the very popular Hugging Face NLP library:

New (old) book I am attempting to read, we’ll see if I can get through it:

Be good everyone! 👋
Disclosures
While the author of this publication is a Partner with Cota Capital Management, LLC (“Cota Capital”), the views expressed are those of the writer author alone, and do not necessarily reflect the views of Cota Capital or any of its affiliates. Certain information presented herein has been provided by, or obtained from, third party sources. The author strives to be accurate, but neither the author nor Cota Capital do not guarantees the accuracy or completeness of any information.
You should not construe any of the information in this publication as investment advice. Cota Capital and the author are not acting as investment advisers or otherwise making any recommendation to invest in any security. Under no circumstances should this publication be construed as an offer soliciting the purchase or sale of any security or interest in any pooled investment vehicle managed by Cota Capital. This publication is not directed to any investors or potential investors, and does not constitute an offer to sell — or a solicitation of an offer to buy — any securities, and may not be used or relied upon in evaluating the merits of any investment.
The publication may include forward-looking information or predictions about future events, such as technological trends. Such statements are not guarantees of future results and are subject to certain risks, uncertainties and assumptions that are difficult to predict. The information herein will become stale over time. Cota Capital and the author are not obligated to revise or update any statements herein for any reason or to notify you of any such change, revision or update.