
Gradient Ascent #5
Infrastructure abstraction, future of serverless

Welcome to the 5th edition of Gradient Ascent. I’m Albert Azout, a prior entrepreneur and current Partner at Cota Capital. On a regular basis I encounter interesting scientific research, startups tackling important and difficult problems, and technologies that wow me. I am curious and passionate about machine learning, advanced computing, distributed systems, and dev/data/ml-ops. In this newsletter, I aim to share what I see, what it means, and why it’s important. I hope you enjoy my ramblings!
Is there a founder I should meet?
Send me a note at albert@cotacapital.com
Want to connect?
Find me on LinkedIn, Angelist, Twitter
What is the future of serverless computing?

In the beginning… 😇
A core tenet of higher level intelligence is the ability to reason abstractly—to suppress detail, ignore nuance and noise, and focus on generalized rules and concepts. Without this requisite ability, we would stumble in novel situations, and fail to discover the intricate mosaic of patterns across everyday experience. We would be stuck, forever in the minutiae. Progress would be halted.
Of course, abstraction also unfolds at the systems level. It was abstraction that enabled the computer industry, layer upon layer, from semiconductor physics through to the application, each subsequent layer enabling a world of contributors above.
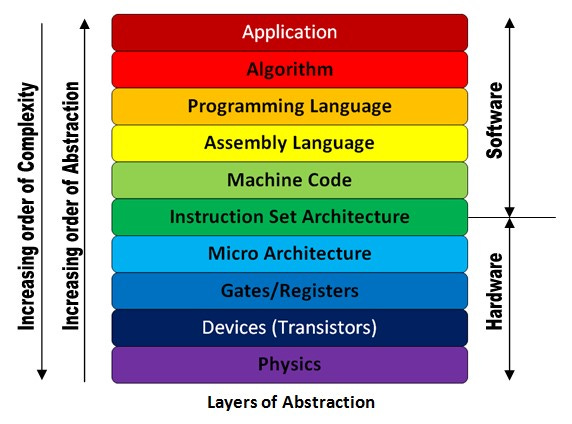
Similarly, cloud computing, over the last decade or so, has evolved its own levels of (infrastructure) abstraction. In the cloud’s early days, virtual machines enabled developers to recreate their local environments on the cloud, which simplified the transition of existing workloads. And for cloud service providers and hyperscalers, virtualization optimized hardware resource utilization and multi-tenancy. While virtualization was a necessary first step, developers are ever-demanding—their end goal being to focus exclusively on application logic and remove the operational overhead of maintaining infrastructure (availability, geographic distribution, load balancing, autoscaling, monitoring and logging, upgrades, etc).

Serverless emerged as a new paradigm, providing a high-level computing abstraction (AWS Lambda launched in 2014 and Google Cloud Functions in 2016), allowing programmers to deploy code written in a high-level language (i.e. Python, node.js), specify events and triggers that execute these functions with unlimited elasticity, and subsequently pay only for the resources utilized (versus the resources allocated). The serverless model unbundles computation from storage (i.e. Amazon S3)—stateless functions read and write to a decoupled storage system—and the two are priced independently.
Today’s serverless computing represents the extreme progression of a trend towards logical disaggregation of software in which developers split applications into components, each specialized to a purpose, running a scaling independently, and having its own resource profile [source].
However, the serverless abstraction is an idealization. In practice, several challenges exist:
At the platform level. (1) functions have limited lifetimes (15 minutes in the case of AWS Lambda), (2) I/O bottlenecks (via connection to cloud services), (3) communicate through slow storage (i.e. for managing application state), (4) have no access to specialized hardware accelerators (i.e. GPUs are critical for high performance applications like ML), and (5) processes are not individually addressable which requires the need for passing data through (slow) storage.
At the developer level. (1) function limited lifetimes destroy state and disallow long application execution times, (2) implicit parallel execution means that containers can run simultaneously, creating the need to manage transactions (3) at-least-once execution can cause data duplication in the case of temporary errors. To work around these issues, for more involved applications (that are not embarrassingly parallel), developers typically need additional code to manage the execution environment (state management, transaction management, unique identifiers) thereby violating the serverless abstraction [Formal Foundations of Serverless Computing]. Challenges are magnified when composing multiple serverless functions in a data workflow (several platforms aim to address function chaining including OpenWhisk, Amazon Step Functions).
In reading through the literature and exploring various projects, modern serverless platforms address these concerns in the following ways:
Fast data access - by placing code next to data, in-memory or distributed data stores, etc (i.e. Plasma Object Store). In addition, using data-centric, domain specific languages (DSL) like Tensorflow will enable intelligent compute and storage planning based on how data flows through the computation graph.
Fast scale-up times - fast elasticity with no cold-start, node caching, application-aware autoscaling.
Support for multiple types of workloads - stateless and stateful, batch and streaming, I/O and compute intensive (ML). In the case of ML, the support for heterogenous stages including feature transformation, training, and hyperparameter optimization.
Support for hardware accelerators - dynamic decisions about where to allocate computation based on service level requirements of application.
Long-running, addressable virtual agents - software agents that persist in the cloud (i.e. Ray actors), maintain state, and are directly accessible.
Enhanced support for function composition - super-easy chaining of functions and also supporting multiple libraries as part of dataflows.
Portable - should work on (any) cloud, edge, kubernetes, local computer, etc.
The following frameworks are notable: the team at Iguazio are developers of the Nuclio serverless platform (thanks @yaron for walking me through the platform this week). And of course, Ray (video). I have also been noticing the following patterns and trends emerging:
Frameworks that provide a seamless transition from code to distributed computing (Dask, Modin, Temporal—thanks @lennypruss).
Convergence of networking infrastructure and serverless/cloud edge (CloudFlare Workers, Amazon Wavelength, Fastly Compute@Edge)
Lots of progress to be expected from the serverless world…
Non Sequiturs
A must watch…

Great podcast with Dileep George from Vicarious…
Disclosures
While the author of this publication is a Partner with Cota Capital Management, LLC (“Cota Capital”), the views expressed are those of the writer author alone, and do not necessarily reflect the views of Cota Capital or any of its affiliates. Certain information presented herein has been provided by, or obtained from, third party sources. The author strives to be accurate, but neither the author nor Cota Capital do not guarantees the accuracy or completeness of any information.
You should not construe any of the information in this publication as investment advice. Cota Capital and the author are not acting as investment advisers or otherwise making any recommendation to invest in any security. Under no circumstances should this publication be construed as an offer soliciting the purchase or sale of any security or interest in any pooled investment vehicle managed by Cota Capital. This publication is not directed to any investors or potential investors, and does not constitute an offer to sell — or a solicitation of an offer to buy — any securities, and may not be used or relied upon in evaluating the merits of any investment.
The publication may include forward-looking information or predictions about future events, such as technological trends. Such statements are not guarantees of future results and are subject to certain risks, uncertainties and assumptions that are difficult to predict. The information herein will become stale over time. Cota Capital and the author are not obligated to revise or update any statements herein for any reason or to notify you of any such change, revision or update.