
Gradient Ascent #8
Stochastic gradient descent, automatic differentiation, saddle points

Welcome to the 8th edition of Gradient Ascent. I’m Albert Azout, a prior entrepreneur and current Partner at Cota Capital. On a regular basis I encounter interesting scientific research, startups tackling important and difficult problems, and technologies that wow me. I am curious and passionate about machine learning, advanced computing, distributed systems, and dev/data/ml-ops. In this newsletter, I aim to share what I see, what it means, and why it’s important. I hope you enjoy my ramblings!
Is there a founder I should meet?
Send me a note at albert@cotacapital.com
Want to connect?
Find me on LinkedIn, Angelist, Twitter
Stochastic Gradient Descent (SGD) is by no doubt the workhorse of deep learning—a critical component in deep learning’s success and ubiquity—well-suited for optimizing deep learning networks whose solutions are non-convex. The aim of SGD and its variants (momentum, Nesterov accelerated gradient, Adagrad, Rmsprop, etc) is to discover a local minima in the very hilly terrain of the network’s loss landscape.
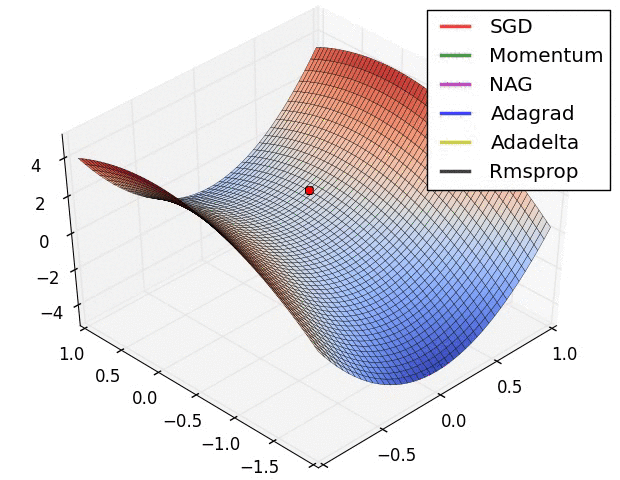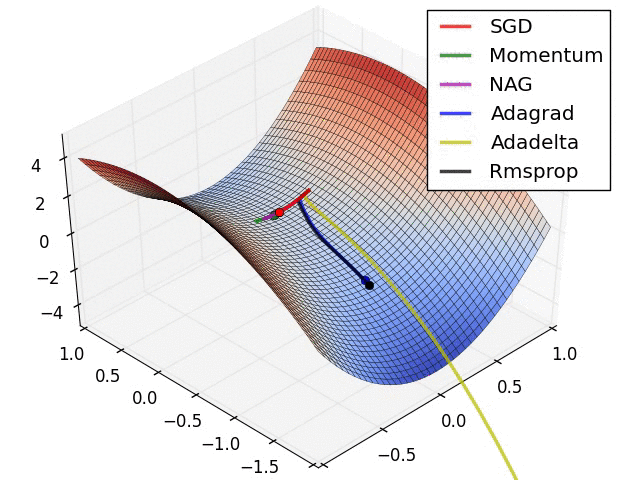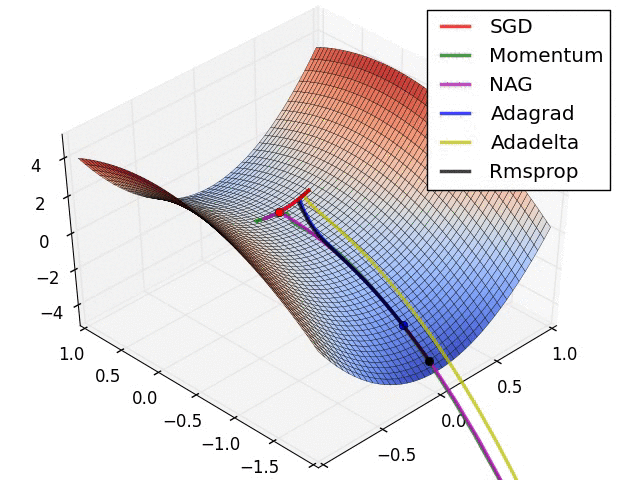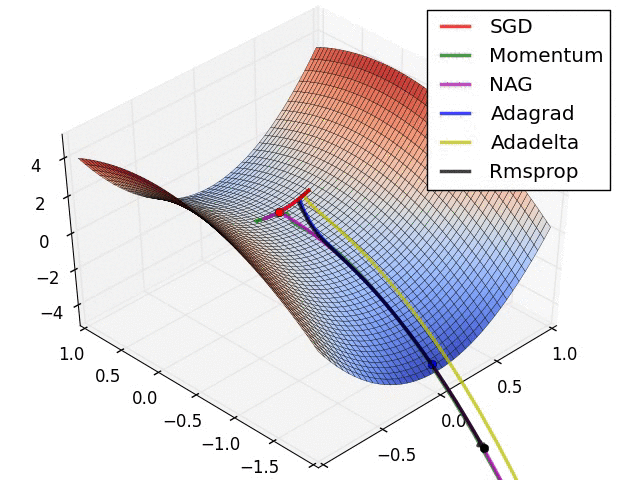
In today’s deep learning frameworks (TensorFlow, PyTorch, etc), the calculation of SGD is abstracted away from engineers via automatic differentiation (backprop is a special case). Automatic differentiation (autodiff) converts a computational graph (example below) into a sequence of primitive operations with specified routines for computing derivatives.

The autodiff backprop abstraction in ML frameworks has catalyzed a significant amount of scientific progress and has certainly led to the many large-scale deep learning models in the wild. But with any abstraction, there are both pros and a cons. On one hand, machine learning scientists and engineers focus on mathematics and network topology versus reasoning about the low-level optimizer implementation. On the other hand, we take for granted that solutions found by SGD (a converged optimal set of network parameters) are one of many minima in the loss landscape, each distinct solution providing varying properties. These properties can have a significant impact on the task at hand.
A quick tangent…
Backprop utilizes the error signal from a loss function to adapt neuronal weights (by recursively calculating the chain rule of calculus). The algorithm generalizes not only to supervised learning settings, but also to reinforcement learning (temporal difference or policy gradient) and unsupervised learning (reconstruction loss). Backprop is loosely inspired by adaptive learning in the brain, and is a specific instance of credit assignment—the brain must learn to adapt synaptic strengths in response to error from the environment through feedback mechanisms. This is an evolutionary necessity.
While most believe the brain does not implement backprop for credit assignment, several of backprop’s features are consistent with brain neural networks (below-left a continuum of feedback versus the precision in reducing error, below-right the speed of backprop learning in finding local minima versus other methods [source]).

It is of note that one of the ways that biological brains differ from artificial neural networks (ANNs) is that error feedback in brains not only adapts synaptic weights but also alters the activity states of neurons. In essence, our brain state evolves as we experience or we experience our brain-state 🤪 — perception is unconscious inference.
Back to the topic at hand…
I started thinking more about this area after reading an interesting blog post out of Berkeley’s BAIR lab. The authors discuss some of the shortcomings of SGD, including an intrinsic bias towards ‘easy’ solution (two solutions with the same loss may be qualitatively different, and if one is easier to find, it is likely to be the only solution found by SGD). In aiming to find a diverse set of solutions to a task, they introduce an algorithm called Ridge Rider (RR), which simultaneously and recursively follows multiple orthogonal directions of negative curvature from a saddle point (that is a mouthful, but I point you to the paper for the very neat technical details).
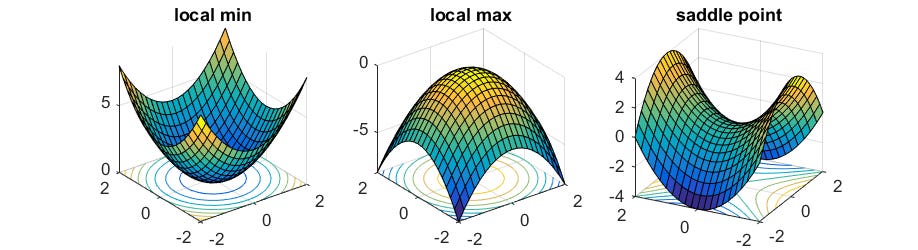
Why is this research important?
Whether this particular algorithm ends up being popularized or not, this area of research is nonetheless important. The intuition is that optimization algorithms should explore a range of solutions that are diverse in the semantics that are important to humans/tasks, assigning credit not myopically but in the context of classes of solutions that address important task dimensions. Inevitably, this approach transforms the optimization problem into a search problem. Indeed, the characteristics and implications of sets of solutions should be a key component in MLOps pipelines—model training, model stability, and observability.
Happy Thanksgiving 🦃 everyone!
Disclosures
While the author of this publication is a Partner with Cota Capital Management, LLC (“Cota Capital”), the views expressed are those of the writer author alone, and do not necessarily reflect the views of Cota Capital or any of its affiliates. Certain information presented herein has been provided by, or obtained from, third party sources. The author strives to be accurate, but neither the author nor Cota Capital do not guarantees the accuracy or completeness of any information.
You should not construe any of the information in this publication as investment advice. Cota Capital and the author are not acting as investment advisers or otherwise making any recommendation to invest in any security. Under no circumstances should this publication be construed as an offer soliciting the purchase or sale of any security or interest in any pooled investment vehicle managed by Cota Capital. This publication is not directed to any investors or potential investors, and does not constitute an offer to sell — or a solicitation of an offer to buy — any securities, and may not be used or relied upon in evaluating the merits of any investment.
The publication may include forward-looking information or predictions about future events, such as technological trends. Such statements are not guarantees of future results and are subject to certain risks, uncertainties and assumptions that are difficult to predict. The information herein will become stale over time. Cota Capital and the author are not obligated to revise or update any statements herein for any reason or to notify you of any such change, revision or update.